前言
前面第一篇介绍了Tomcat的整体架构,能让我们在宏观上对Tomcat的运转流程有一个认识,但原理毕竟只是理论,这篇博客就来从源码入手,分析Tomcat的的初始化、启动、各个组件的构建、一次请求的分发、生命周期的管理等内容。
从初始化开始
Tomcat启动有三种方式,第一种是直接通过org.apache.catalina.startup.Bootstrap类的main方法,这也是最早出现的一种方式,需要自己去配置server.xml文件;第二种是通过内嵌的方式,现在比较流行的SpringBoot也就是内嵌的org.apache.catalina.startup.Tomcat类;第三种是使用脚本,这里对应的是Tomcat根目录的bin目录下的startup.sh(Windows下面是startup.bat, 其它一样)脚本文件开始的,像早期的web项目、ssm这些开发和部署都是使用的这种方式,这个脚本文件主要做的事情就是设置一些环境变量,然后会调用catalina.sh文件,这几种方式做的都是同样的事,会先获取一些初始化参数。其实不管哪种方式,最终还是都会到Java类,走一样的流程。Bootstrap类首先会调用init()方法,看下面的代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
| public void init() throws Exception { ...... Class<?> startupClass = catalinaLoader.loadClass("org.apache.catalina.startup.Catalina"); Object startupInstance = startupClass.getConstructor().newInstance(); String methodName = "setParentClassLoader"; Class<?> paramTypes[] = new Class[1]; paramTypes[0] = Class.forName("java.lang.ClassLoader"); Object paramValues[] = new Object[1]; paramValues[0] = sharedLoader; Method method = startupInstance.getClass().getMethod(methodName, paramTypes); method.invoke(startupInstance, paramValues); catalinaDaemon = startupInstance; }
|
Bootstrap类会会通过反射的方式调用Catalina类的的setParentClassLoader()方法,设置当前Server的扩展类加载器,接着看看Bootstrap类main方法接下来的代码
1 2 3
| daemon.load(args); daemon.start();
|
这就是在根据初始化的命令参数的进行后续的操作, 首先会调用load()方法, 这个方法同样是以反射方式调用Catalina类的load方法,这是个比较重要的方法,看看源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84
| public void load() { ...... Digester digester = createStartDigester(); InputSource inputSource = null; InputStream inputStream = null; File file = null; try { try { file = configFile(); inputStream = new FileInputStream(file); inputSource = new InputSource(file.toURI().toURL().toString()); } catch (Exception e) { if (log.isDebugEnabled()) { log.debug(sm.getString("catalina.configFail", file), e); } } if (inputStream == null) { try { inputStream = getClass().getClassLoader() .getResourceAsStream(getConfigFile()); inputSource = new InputSource (getClass().getClassLoader() .getResource(getConfigFile()).toString()); } catch (Exception e) { if (log.isDebugEnabled()) { log.debug(sm.getString("catalina.configFail", getConfigFile()), e); } } } if (inputStream == null) { try { inputStream = getClass().getClassLoader() .getResourceAsStream("server-embed.xml"); inputSource = new InputSource (getClass().getClassLoader() .getResource("server-embed.xml").toString()); } catch (Exception e) { if (log.isDebugEnabled()) { log.debug(sm.getString("catalina.configFail", "server-embed.xml"), e); } } } ...... try { inputSource.setByteStream(inputStream); digester.push(this); digester.parse(inputSource); } catch (SAXParseException spe) { log.warn("Catalina.start using " + getConfigFile() + ": " + spe.getMessage()); return; } catch (Exception e) { log.warn("Catalina.start using " + getConfigFile() + ": " , e); return; } } finally { if (inputStream != null) { try { inputStream.close(); } catch (IOException e) { } } } ...... try { getServer().init(); } catch (LifecycleException e) { if (Boolean.getBoolean("org.apache.catalina.startup.EXIT_ON_INIT_FAILURE")) { throw new java.lang.Error(e); } else { log.error("Catalina.start", e); } } ...... }
|
看到第一行会调用createDigester()方法创建一个Digester对象的实例,那么这个对象是干嘛的呢?用来解析xml文件,将xml里面配置的属性映射到对应的Java对象,看看这个方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
| protected Digester createStartDigester() { Digester digester = new Digester(); ...... digester.addObjectCreate("Server", "org.apache.catalina.core.StandardServer", "className"); digester.addSetProperties("Server"); digester.addSetNext("Server", "setServer", "org.apache.catalina.Server"); digester.addObjectCreate("Server/Listener", null, "className"); digester.addSetProperties("Server/Listener"); digester.addSetNext("Server/Listener", "addLifecycleListener", "org.apache.catalina.LifecycleListener"); digester.addObjectCreate("Server/Service", "org.apache.catalina.core.StandardService", "className"); ...... return digester; }
|
这个方法首先直接实例化一个Digester对象, 接着主要是用来解析server.xml文件,该文件不存在时再获取其它的配置文件,这里看源码就很容易清楚了, 这个方法里面定义了一系列的解析规则,使用这些规则经能把需要的属性注入到对应的Java对象实例,再回到load()方法,里面有这么一行
Digester对象内部维护了一个栈,这行代码就是push当前Catalina对象到Digester内部维护的栈的栈顶。以Server的注入为例,这里就是首先用digester.addObjectCreate()方法查看xml文件中Server标签中的className属性是否为空,为空则实例化一个StandardServer对象,并把此对象push到栈顶,然后使用digester.addSetProperties()方法设置在配置文件中与它相关的属性,最后再使用 digester.addSetNext()方法,拿到当前栈顶元素的下一层的元素,在这里也就是Catalina对象,然后调用它的setServer()方法把当前栈顶元素当作参数传入,这样一来当前Catalina的Server已经实例好了。栈顶存放的始终是上一层的实例化对象, 解析到的当前层级的xml标签如果还有下一层,继续按照配置好的规则进行解析,层层递进,用这种方式,就可以将Tomcat各个组件的一些属性或它的子组件装配好。再回到load()方法,解析完xml文件后最终会调用 getServer().init()方法,这个Server也就是前面实例化好的StandardServer,直接跟进去看看它的init()方法,结果发现这个方法是在它的父类LifecycleBase实现的,而这个类看名字就知道是和生命周期有关的,所以引出了下面的内容。
生命周期
其实在第一篇博客里面已经简单介绍过了,不过这里还要补充一些,前面说到LifecycleBase类,它是实现了Lifecycle接口,把生命周期的状态的转变与维护、事件的触发以及监听器的添加与删除等公共的逻辑放到这个类来做,子类就可以在某个生命周期的时候专注实现自己的逻辑,看看这张类图
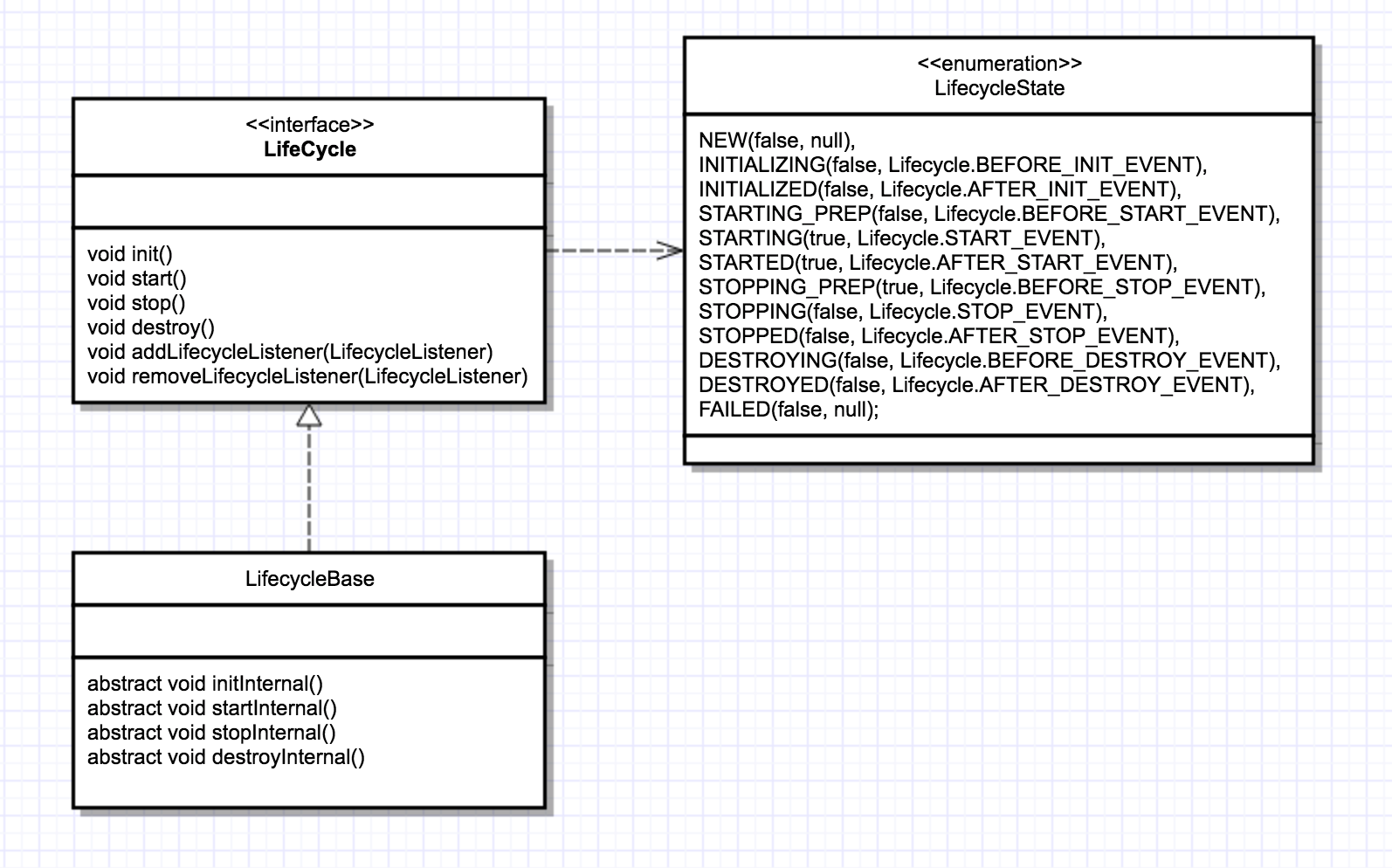
为了防止与接口里面的方法重名,所以LifecycleBase类往原来的生命周期方法后面加了internal,子类只要实现这些方法就可以了,直接来看看具体的代码吧,还是接着前面的init()方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
| public final synchronized void init() throws LifecycleException { if (!state.equals(LifecycleState.NEW)) { invalidTransition(Lifecycle.BEFORE_INIT_EVENT); } try { setStateInternal(LifecycleState.INITIALIZING, null, false); initInternal(); setStateInternal(LifecycleState.INITIALIZED, null, false); } catch (Throwable t) { handleSubClassException(t, "lifecycleBase.initFail", toString()); } }
|
这个方法逻辑比较简单,主要逻辑都写清楚了,setStateInternal()方法会拿到生命状态对应的事件,然后将事件通知到已经注册到该组件的监听器。initInternal()是抽象方法,给子类实现,其它生命周期的方法也都是类似的逻辑,其实这就是设计模式中的模板方法模式,把公共逻辑给抽象父类做了,具体的子类再去填充已经规定好的模板,这里也就是xxinternal()方法。接着回到主线,既然该方法是给子类实现的,我们看到LifecycleBase的子类StandardServer的initInternal()方法
1 2 3 4 5 6 7
| protected void initInternal() throws LifecycleException { ...... for (int i = 0; i < services.length; i++) { services[i].init(); } }
|
核心功能就是初始化Service,进入Service,而Service是我们从Socket连接到Web应用真正的管家,管理着Connector和Container两大核心组件。看看Service的initInternal()方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
| protected void initInternal() throws LifecycleException { super.initInternal(); if (engine != null) { engine.init(); } for (Executor executor : findExecutors()) { if (executor instanceof JmxEnabled) { ((JmxEnabled) executor).setDomain(getDomain()); } executor.init(); } mapperListener.init(); synchronized (connectorsLock) { for (Connector connector : connectors) { connector.init(); } } }
|
确实是分别调用了上层容器(Engine)和连接器(Connector)的初始化方法,同时初始化了线程池和MapperListener监听器,这几个玩意一个个来,首先是Engine,调用了engine的init()方法后进入了容器的部分。容器的虽然也是从LifecycleBase继承下来的,但因为容器和其它组件相比也有自己的一部分逻辑,且容器(Container)的子组件较多,所以Tomcat用了一个ContainerBase类来继承了LifecycleBase,并实现了Container接口,简单描述一下ContainerBase做了哪些事情
- 1.绑定父容器,获取父容器相关的信息;管理子容器,实现了容器及其监听器获取、添加、删除,以及容器状态的维护,数据销毁与事件的发送等通用方法,
- 2.维护了容器的重要组成元素Pipeline,并提供了操作Valve的通用方法
- 3.后台任务线程的管理,可以进行周期性的检查并重载相关的配置
还是借助类图,才能有一个比较清晰的了解,如下
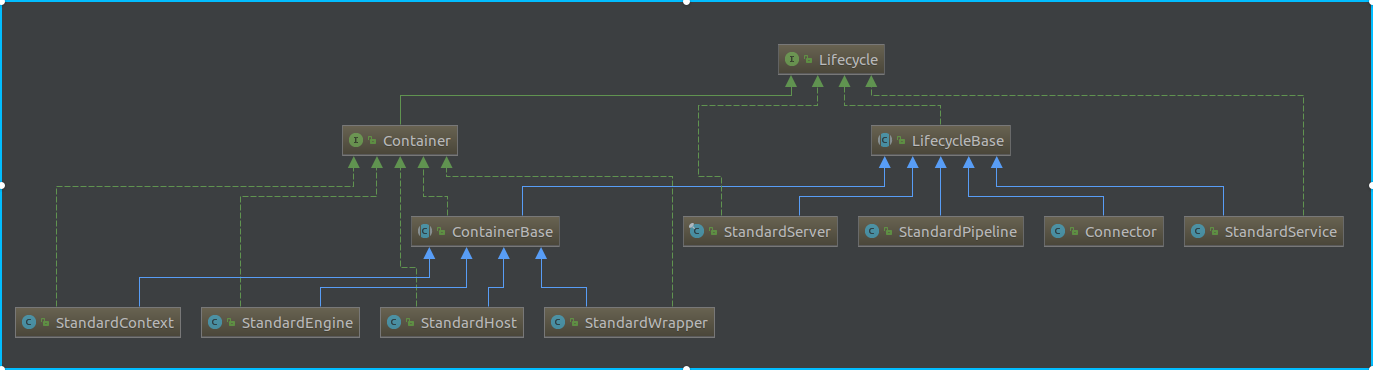
ContainerBase的initInternal()方法会实例化一个Executor线程池(默认线程数量是1),用来启动、停止子容器。接着看到MapperListener是可以实现热部署的,当Web应用的部署信息发生变化时,就会将对应的事件通知到该监听器,然后监听器根据接收到的事件更新Mapper的信息,这里的init()方法是直接用的父类的,把当前对象在JMBean里面进行注册,与主题无关就不多说了,下面来介绍一下线程池。
Tomcat内部的线程池
Tomcat的线程池是继承了jdk的线程池,并实现了Lifecycle接口,对应的类是org.apache.catalina.core.StandardThreadExecutor,它的是内部持有一个ThreadExecutor对象,真正的线程池相关的逻辑就是这个定制版的ThreadExecutor来做的,接下来看看org.apache.tomcat.util.threads.ThreadExecutor对比jdk的线程池做了哪些优化呢?首先得搞清楚jdk的线程池执行的流程是怎样的,概括来说
- 1.任务数量还未达到coreSize个时,来一个任务就创建一个新线程
- 2.再来任务时,就把任务丢到队列里面让所有的线程去抢;如果队列满了就创建临时线程
- 3.如果总线程数达到maximumPoolSize,则执行拒绝策略
而Tomcat的线程池会在上述第3步(当然Tomcat也可以配置线程池的核心线程预启动),达到最大数后不会直接执行拒绝策略,会再尝试添加任务到队列中,看看代码1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
| public void execute(Runnable command, long timeout, TimeUnit unit) { submittedCount.incrementAndGet(); try { super.execute(command); } catch (RejectedExecutionException rx) { if (super.getQueue() instanceof TaskQueue) { final TaskQueue queue = (TaskQueue)super.getQueue(); try { if (!queue.force(command, timeout, unit)) { submittedCount.decrementAndGet(); throw new RejectedExecutionException("Queue capacity is full."); } } catch (InterruptedException x) { submittedCount.decrementAndGet(); throw new RejectedExecutionException(x); } } else { submittedCount.decrementAndGet(); throw rx; } } }
|
可以看到具体的实现方式是抛出拒绝异常进行捕获后,再次尝试入队失败再手动抛出异常,这样做的原因主要是可能再次添加任务时有任务消费完了,就能继续添加任务到队列中了。这里注意还有submittedCount这么一个原子变量,用来统计已经提交到任务队列中但还未执行的任务数量,搞这么一个变量的原因肯定是和任务队列有关。首先看看jdk的队列LinkedBlockingQueue,如果指定了队列的大小还好,如果没指定默认值是Integer.MAX_VALUE,Integer的最大值,当任务数量过大,核心线程远远处理不过来的时候,还不停的添加任务到队列,并且只要没到队列的最大值就不会创建新的临时线程来处理,最后导致的结果可能就是堆内存溢出,之前任务过多时只是丢掉一些任务,现在是直接影响到应用的正常使用… Tomcat线程池的任务队列org.apache.tomcat.util.threads.TaskQueue就针对这一点进行了优化,具体实现还是继承了LinkedBlockingQueue,只要在关键点做处理就可以,直接看入队的代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
| public boolean offer(Runnable o) { if (parent==null) return super.offer(o); if (parent.getPoolSize() == parent.getMaximumPoolSize()) return super.offer(o); if (parent.getSubmittedCount()<=(parent.getPoolSize())) return super.offer(o); if (parent.getPoolSize()<parent.getMaximumPoolSize()) return false; return super.offer(o); }
|
代码的逻辑很清晰了,这样一来就能很好的解决了没达到任务队列大小时无法创建新的线程来进行处理的情况。对于jdk的线程池,现在推荐的做法都是建议进行显示的创建来指定相关的属性,特别是对于任务队列显式的指定最大数量,这样才能更好在源头上避免问题的产生,因为即使是能创建新的线程来进行处理,但任务数量增加太快时还是可能出现处理不过来的情况。再回到刚开始说的,使用StandardThreadExecutor类,主要是方便了线程池与Tomcat的组件的生命周期的统一管理,它的init()也与MapperListener一样,也直接跳过了,注意这里初始化时StandardThreadExecutor内部的线程池和任务队列并没有实例化,而是在启动时才实例化的,这里的Executor其实会通过反射的方式设置到Connector的ProtocolHandler,也就是前面的createDigester()里面配置了这个规则。接下来看看Connector的初始化方法主要做了哪些事
Connector的初始化
Connector作为管理连接、解析参数,构建请求、响应的对象,是理解Tomcat的工作流程极其重要的部分,第一篇说过Tomcat其实是一个应用服务器+Servlet容器,而Servlet容器是为了遵循JavaWeb开发的规范,在其它语言或框架可能就不会管这什么Servlet规范了,对于任何服务器框架来说,连接的管理都是最核心的部分,分析的时候前提是对Tomcat的整体有个大概了解。直接看到Connector的initInternal()方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
| protected void initInternal() throws LifecycleException { adapter = new CoyoteAdapter(this); protocolHandler.setAdapter(adapter); if (null == parseBodyMethodsSet) { setParseBodyMethods(getParseBodyMethods()); } ...... try { protocolHandler.init(); } catch (Exception e) { throw new LifecycleException( sm.getString("coyoteConnector.protocolHandlerInitializationFailed"), e); } }
|
这里的protocolHandler实际是在Connector实例化的时候在构造方法里面利用反射构建的,前面说过这个对象是对应用层协议的抽象(不熟悉的看下第一篇连接器相关的小节),这里比较重要的是与一个Adapter实例进行了绑定,而这个实例是用来实现从连接器到容器的请求、响应对象适配工作的,接下来我们可以看到protocolHandler调用了它的init()方法,这里为了方便还是拿来前面的类图
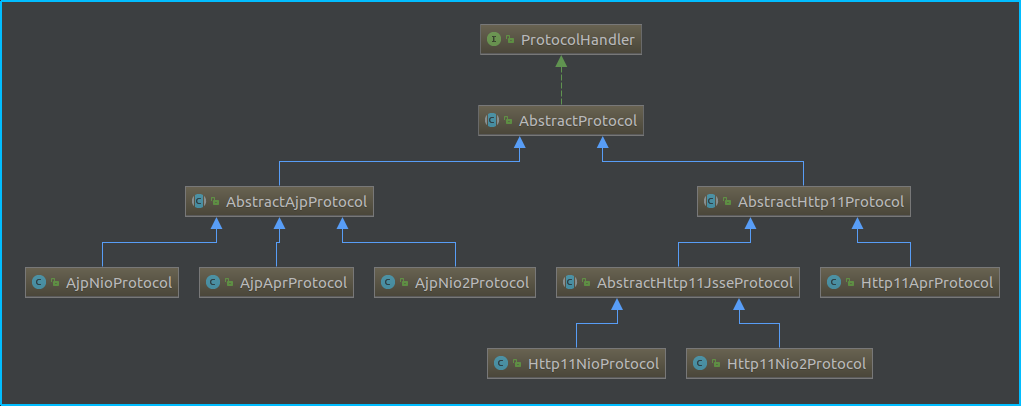
我们的目的是搞清楚工作流程,所以以Http11NioProtocolHandler-NioEndpoint这条线来摸清楚流程,继续跟进去发现最初的init()方法是在AbstractHttp11Protocol这个抽象父类,这个类的构造方法如下
1 2 3 4 5 6 7 8 9 10
| public AbstractHttp11Protocol(AbstractEndpoint<S,?> endpoint) { super(endpoint); setConnectionTimeout(Constants.DEFAULT_CONNECTION_TIMEOUT); ConnectionHandler<S> cHandler = new ConnectionHandler<>(this); setHandler(cHandler); getEndpoint().setHandler(cHandler); }
|
这里面会调用父类的构造方法,把Endpoint传进去,这是我们处理连接和读写事件干事的地方,稍后在详细描述,看到接下来几行代码会实例化ConnectorHandler,并且与当前Endpoint进行绑定,这个ConnectHandler主要的职责是用来管理SocketProcessor,后面在源码中会看到的。回到主线,AbstractHttp11Protocol的init()方法首先会进行协议升级相关的配置,这个我们不用管,接着会调用父类AbstractProtocol的init()方法,看看它的代码
1 2 3 4 5 6 7 8
| public void init() throws Exception { ... String endpointName = getName(); endpoint.setName(endpointName.substring(1, endpointName.length()-1)); endpoint.setDomain(domain); endpoint.init(); }
|
这里逻辑也比较简单,所以我们继续跟进到NioEndPoint的init()方法,这里还是把类图拿过来
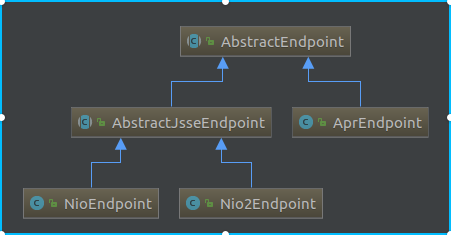
同样它的init()方法也是在最终的抽象父类AbstractEndpoint,主要有这么一段逻辑
1 2 3 4
| if (bindOnInit) { bindWithCleanup(); bindState = BindState.BOUND_ON_INIT; }
|
bindOnInit指在是否初始化时进行端口的绑定,默认是true,它会调用bindWithCleanup()方法
1 2 3 4 5 6 7 8 9 10 11
| private void bindWithCleanup() throws Exception { try { bind(); } catch (Throwable t) { ExceptionUtils.handleThrowable(t); unbind(); throw t; } }
|
这个bind()也是一个抽象模板方法,目的是给子类实现的,所以我们的init()方法最终到了NioEndpoint的bind()方法,上代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
| public void bind() throws Exception { initServerSocket(); if (acceptorThreadCount == 0) { acceptorThreadCount = 1; } if (pollerThreadCount <= 0) { pollerThreadCount = 1; } setStopLatch(new CountDownLatch(pollerThreadCount)); initialiseSsl(); selectorPool.open(); }
|
首先看到initServerSocket()方法会先初始化ServerSocket,也就是如下几行代码
1 2 3 4
| serverSock = ServerSocketChannel.open(); socketProperties.setProperties(serverSock.socket()); InetSocketAddress addr = new InetSocketAddress(getAddress(), getPortWithOffset()); serverSock.socket().bind(addr,getAcceptCount()); serverSock.configureBlocking(true);
|
需要清楚的是对于ServerSocketChannel,Tomcat直接使用的阻塞的方式来监听连接,也无需注册到Selector,确实意义不大,反正建立连接后就不归它管了。接着会初始化Acceptor和Poller的线程数量,在第一篇里面介绍过,Acceptor是用来接收新的连接的线程,建立连接后就把连接通道Channel交给众多Poller中的一个;Poller是用来检测已经建立好的连接的IO事件,对应的也就是jdk的selector(多路复用器),具体的代码还在后面,继续看到bind()方法的最后一行,会调用selectorPool的open()方法,那么这个selectorPool又是个啥东西呢?selectorPool是org.apache.tomcat.util.net.NioSelectorPool的一个实例对象,它的职责其实是作为一个辅助Selector,而前面说到的Poller一般称被称为主Selector,后续在进行具体分析。
正式启动
前面从讲了从init()方法开始主要做的事情,接下来就看看Catalina的start()方法,上代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
| public void start() { ...... getServer().start(); if (useShutdownHook) { if (shutdownHook == null) { shutdownHook = new CatalinaShutdownHook(); } Runtime.getRuntime().addShutdownHook(shutdownHook); } if (await) { await(); stop(); } }
|
代码精简后,这里首先调用了getServer().start(),这里先放一放,接着看看后面的代码,首先判断是否useshutdownHook,默认为true。接着往Runtime里面添加了了一个CatalinaShutdownHook,其实也就是一个Thread对象实例,它的里面就是停止和进行资源回收的逻辑,这是挺实用的一个东西,也就是为了防止应用异常停止的时候资源得不到正确回收,以前写Java的gui程序的时候就很容易出现明明调用了System.exit(),但进程还是运行着,注册到Runtime,也就是当前应用的运行环境后,应用停止时会自动调用它里面的逻辑,这一点是由JVM来进行保证的,JVM的进程在完全退出前会自动去执行所有注册了的ShutdownHook的逻辑;此外,后面await()方法还通过启动一个Socket服务端,来监听SHUTDOWN消息,验证通过后进入stop流程。接着直接跳到StandardServer的start()方法,前面初始化时说过,这些生命周期相关的方法基本的逻辑都交给父类去处理了,子类直接进行xxInternal()方法进行自己的逻辑,所以我们直接看到startInternal()方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14
| protected void startInternal() throws LifecycleException { fireLifecycleEvent(CONFIGURE_START_EVENT, null); setState(LifecycleState.STARTING); globalNamingResources.start(); synchronized (servicesLock) { for (int i = 0; i < services.length; i++) { services[i].start(); } } }
|
逻辑很简单,首先通知已注册的监听器,包括正常对生命周期进行监控的,以及需要加载某些配置的。接着会遍历所有已经添加了的Service,并调用它们的start()方法,这里也直接看到StandardService的startInternal()方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
| protected void startInternal() throws LifecycleException { setState(LifecycleState.STARTING); if (engine != null) { synchronized (engine) { engine.start(); } } synchronized (executors) { for (Executor executor: executors) { executor.start(); } } mapperListener.start(); synchronized (connectorsLock) { for (Connector connector: connectors) { if (connector.getState() != LifecycleState.FAILED) { connector.start(); } } }
|
容器的启动
这里首先会启动Service的首个子容器Engine,我们继续跟进StandardEngine的startInternal()方法,不过它除了打印日志以外没做任何事,是直接调用了父类ContainerBase的startInternal()方法,直接看代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
| protected synchronized void startInternal() throws LifecycleException { Container children[] = findChildren(); List<Future<Void>> results = new ArrayList<>(); for (int i = 0; i < children.length; i++) { results.add(startStopExecutor.submit(new StartChild(children[i]))); } for (Future<Void> result : results) { result.get(); } if (pipeline instanceof Lifecycle) { ((Lifecycle) pipeline).start(); } setState(LifecycleState.STARTING); threadStart(); }
|
这部分是所有容器的公共逻辑,代码也比较简单,首先找到所有的子容器并进行启动,只是这里使用的是Future来提交任务的,与Runnable相比,没多大区别,Future是方便设置任务执行的结果的,然后通过get()来获取,不过这里使用Future也没看到有什么作用,返回值也是Void,估计是为了后期的扩展。看到下面的,接着会调用管道的start()方法,Tomcat的标准实现类是StandardPipeline,它的start()方法会去遍历Pipeline内所有的Valve,并调用它们start()方法,接着看到最后一行threadStart(),它会启动一个线程执行周期性的任务,对应的Runnable就是ContainerBackgroundProcessor,看看它的run方法
1 2 3 4 5 6 7 8 9 10
| while (!threadDone) { try { Thread.sleep(backgroundProcessorDelay * 1000L); } catch (InterruptedException e) { } if (!threadDone) { processChildren(ContainerBase.this); } }
|
只要线程没结束,就不停的执行周期性的任务,接着会调用processChildren(),看看代码
1 2 3 4 5 6 7 8 9 10 11
| protected void processChildren(Container container) { container.backgroundProcess(); Container[] children = container.findChildren(); for (int i = 0; i < children.length; i++) { if (children[i].getBackgroundProcessorDelay() <= 0) { processChildren(children[i]); } } }
|
这些主要就是调用了容器的backgroundProcess(),并递归的所有对所有子容器进行同样的调用,所以可以知道了只要我们在容器里面重写backgroundProcess()方法,就可以做一些周期性执行的任务,并且,例如资源的热加载,session对象有效期的管理等。
线程池与Mapper的启动
还是按照StandardService里面代码的顺序,这里线程池对应的管理者是StandardExecutor,它的启动方法只是把内部真正的ThreadExectuor和TaskQueue实例化,接着来看看MapperListener的startInternal()方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
| public void startInternal() throws LifecycleException { setState(LifecycleState.STARTING); Engine engine = service.getContainer(); if (engine == null) { return; } findDefaultHost(); addListeners(engine); Container[] conHosts = engine.findChildren(); for (Container conHost : conHosts) { Host host = (Host) conHost; if (!LifecycleState.NEW.equals(host.getState())) { registerHost(host); } } }
|
Mapper是比较重要的一个组件,看看上面的代码,findDefaultHost()首先配置默认的主机名,也就是,默认情况下也就是localhost,还是看看图
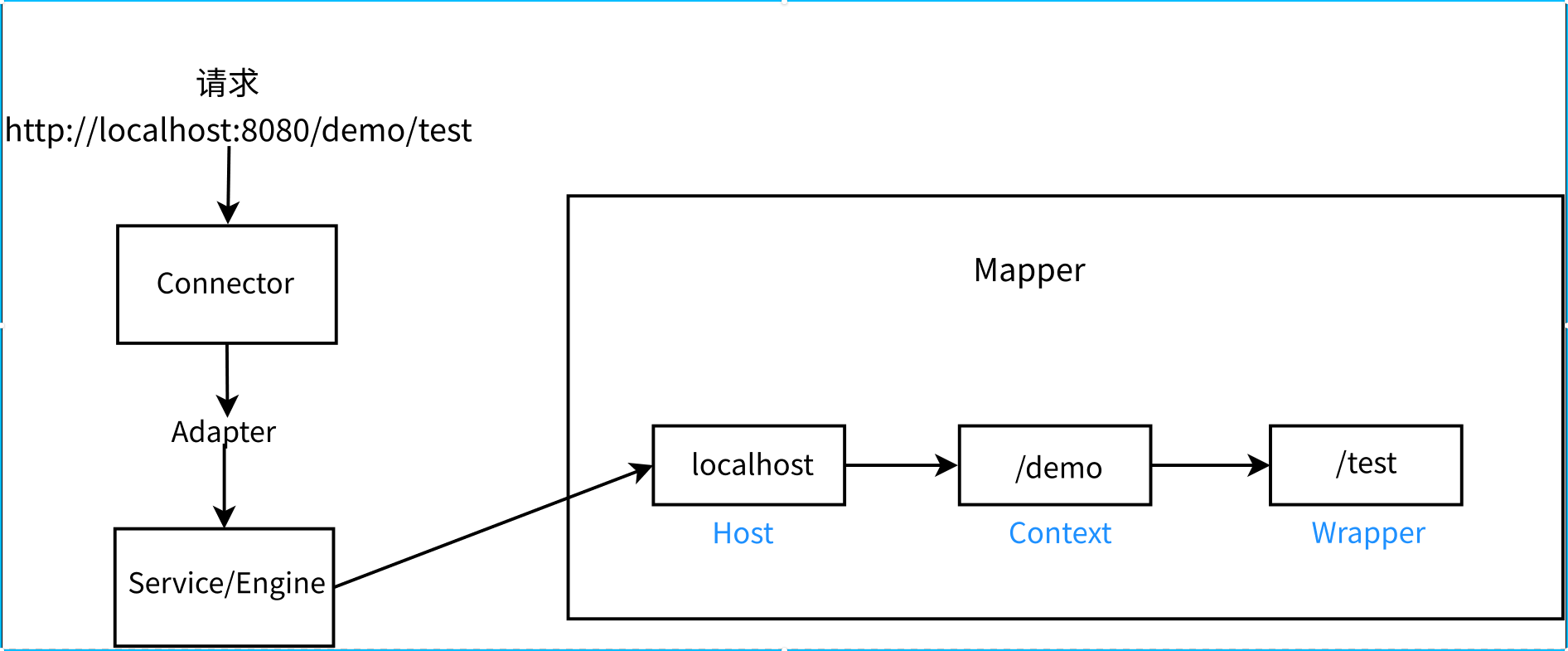
这里就很清楚容器的各层组件表示的具体对象了,实际上这是对于常规的Servlet项目而言,对于平时部署Spring的项目而言,Context和Wrapper其实都是/,把请求和响应对象包装好后在DispatcherServlet的内部再对uri处理,最后会找到Controller里面的映射路径对应的方法。回到上面的代码,接着addListeners()方法会递归的给每个子容器都添加了MapperListener监听器,所以可以知道子容器的Mapper都是共享的同一个,继续接下来的代码就是配置默认的每层组件到子容器的映射。接下来就看连接器的启动了
Connector的启动
Connector的start()方法,里面也是调用了ProtocolHandler的start()方法,所以直接看到它的子类AbstractProtocolHandler的启动方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
| public void start() throws Exception { endpoint.start(); asyncTimeout = new AsyncTimeout(); Thread timeoutThread = new Thread(asyncTimeout, getNameInternal() + "-AsyncTimeout"); int priority = endpoint.getThreadPriority(); if (priority < Thread.MIN_PRIORITY || priority > Thread.MAX_PRIORITY) { priority = Thread.NORM_PRIORITY; } timeoutThread.setPriority(priority); timeoutThread.setDaemon(true); timeoutThread.start(); }
|
它的启动方法主要是做两件事情,调用Endpoint的start(),稍后进行描述;另外一件事情是开启了检测异步Servlet超时的线程,简单说一下,跟异步Servlet相关的processor会放到一个waitingProcessors集合中,因为使用异步的时候,任务的具体处理交给了Tomcat外部的线程,但连接是由Tomcat进行的管理,所以必须保证它的读写有一个时间限制,不然里连接就可能会一直占用着,由于篇幅有限,这里就不讨论异步Servlet有关的了。
EndPoint
回到Endpoint,AbstarctEndpoint的start()只会判断一下没绑定就进行下bind()的逻辑,接着就只有一个给子类的startInternal()方法,所以可以直接看到NioEndPoint的该方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
| public void startInternal() throws Exception { if (!running) { running = true; paused = false; processorCache = new SynchronizedStack<>(SynchronizedStack.DEFAULT_SIZE, socketProperties.getProcessorCache()); eventCache = new SynchronizedStack<>(SynchronizedStack.DEFAULT_SIZE, socketProperties.getEventCache()); nioChannels = new SynchronizedStack<>(SynchronizedStack.DEFAULT_SIZE, socketProperties.getBufferPool()); if ( getExecutor() == null ) { createExecutor(); } initializeConnectionLatch(); pollers = new Poller[getPollerThreadCount()]; for (int i=0; i<pollers.length; i++) { pollers[i] = new Poller(); Thread pollerThread = new Thread(pollers[i], getName() + "-ClientPoller-"+i); pollerThread.setPriority(threadPriority); pollerThread.setDaemon(true); pollerThread.start(); } startAcceptorThreads(); } }
|
到这里就要先好好介绍一下Endpoint里面最重要的几个对象了
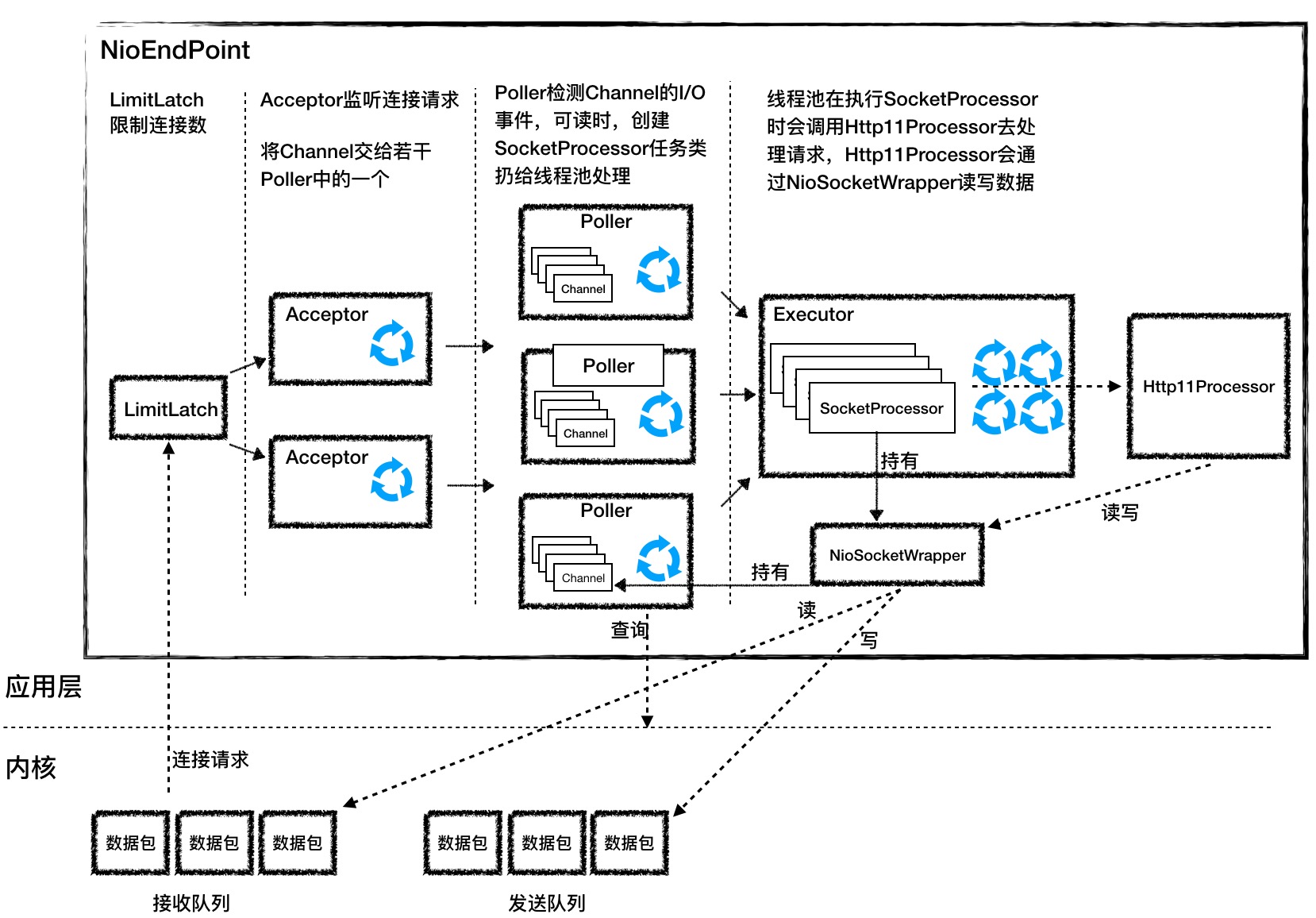
- Acceptor: 用来接收ServerSocketChannel连接请求的对象,会不停的轮询是否有新的连接加入,也就是调用serverSocketAccept()方法,然后把连接返回的SocketChannel使用NioChannel包装,再选择一个Poller进行注册,注册时会再把NioChannel使用NioSocketWrapper(NioEndPoint中SocketWrapperBase的具体实现类)进行包装,并生成一个新的事件PollerEvent,对应的也就是jdk的SelectionKey里面的事件类型,,然后加入到Poller的事件队列中。
Poller: 内部持有一个事件队列和多路复用器(Selector),内部会有一个while(true)循环不停的从事件队列中取出一个事件,把事件注册到持有的Selector,并且会把NioSocketWrapper绑定到对SelectionKey,然后查询是否有事件就绪,接着会把就绪好的事件去丢到SocketProcessor里面放到线程池去处理,SocketProcessor会取出当前的EndPoint中的ConnectionHandler,也就是前面讲的在AbstractEndpoint的构造方法里面实例化的,接着它会把NioSocketWrapper丢到Http11Processor里面进行处理。
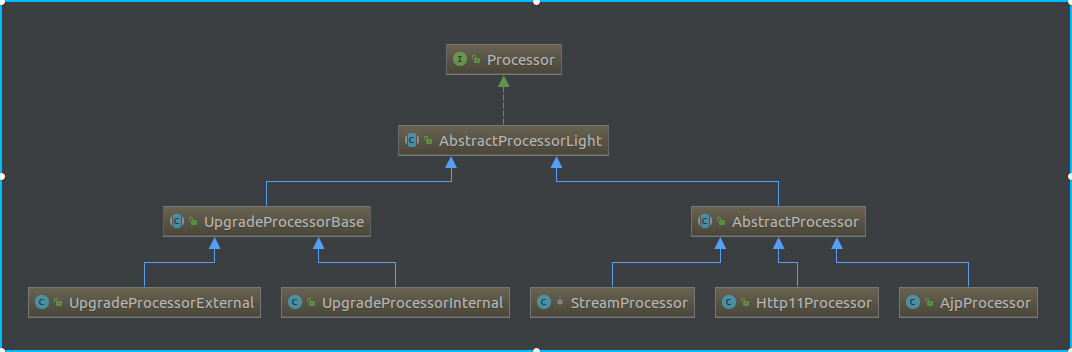
Processor: 可以看看上面的类图,这里我们关注点是Http11Processor。这里面会实例化org.apache.coyote.Request和org.apache.coyote.Response对象,并且持有Http11InputBuffer和Http11OutputBuffer两个对象,这两个对象会真正的从Socket通道读取到具体的数据,当然它的读取还是通过内部持有的NioSocketWrapper,并对请求进行初步的处理,也就是解析请求行和请求头,而请求体是在业务层进行调用时再进行读取和解析。最后会把请求交给Adapter进行处理,Adapter会把coyote包下的Request和Response包装到org.apache.catalina.connector包下的Request和Response,而这两个对象是继承了HttpServletRequest和HttpServletResponse的,再接着请求就会到容器了。
回到上面的代码首先会初始化化3个同步栈,processorCache是用来存储SocketProcessor,evenCache是用来存储Poller里面的Event,nioChannelCache是用来存储NioChanel,它们都是SynchronizedStack的实例,这个对象是Tomcat用来做对象的缓存池的,也就是说把用完的对象丢到缓存池,下次再需要这些对象时就可以重用,用的时候再进行重置;缓冲池拿不到了,再创建新的,用完还是丢回缓存池,直到达到上限。这样做的好处是减少了常用对象的初始、实例化的开销以及减少垃圾收集器对堆内存进行回收的频率,但也有一点是会涉及到多个线程的抢占,有锁的竞争与释放的开销。
接着下面的代码 initializeConnectionLatch()会初始化一个限制连接数量的LimitLatch,Acceptor必须得先拿到锁才能去监听新连接的到来,否则就一直等待,使用这种方式从上层限制了并发连接的数量,保证了正常业务处理的进行,它的实现也是基于jdk中的AQS。接下来的代码就是实例化并启动了Poller和Acceptor的线程,到此请求就能正常的到来了。
一次请求的过程
前面写了那么多,在主线已经把初始化和启动完成了,现在能正常接收并处理请求了,就下来就看看请求是怎么走的,其实界面介绍Endpoint几个组件的时候已经把主要的流程过了一遍,不过还是要来看实际的代码,心里才更加踏实。
Acceptor
要看请求,自然是从连接的到来开始,所以直接看到
Acceptor的run方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
| public void run() { while (endpoint.isRunning()) { state = AcceptorState.RUNNING; try { endpoint.countUpOrAwaitConnection(); U socket = null; try { socket = endpoint.serverSocketAccept(); } catch (Exception ioe) { endpoint.countDownConnection(); ...... } if (endpoint.isRunning() && !endpoint.isPaused()) { if (!endpoint.setSocketOptions(socket)) { endpoint.closeSocket(socket); } } else { endpoint.destroySocket(socket); } } catch (Throwable t) { ...... } } state = AcceptorState.ENDED; }
|
代码进行了精简,可以看到Acceptor会在一个while循环里面,首先看连接数量是否达到上线,然后去监听服务器端的连接请求,连接到来后会获取到一个SocketChannel对象,接着会调用setSocketOptions()方法进行参数的配置,接着会进行下一轮循环,跟进去看看
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
| protected boolean setSocketOptions(SocketChannel socket) { try { socket.configureBlocking(false); Socket sock = socket.socket(); socketProperties.setProperties(sock); NioChannel channel = nioChannels.pop(); if (channel == null) { SocketBufferHandler bufhandler = new SocketBufferHandler( socketProperties.getAppReadBufSize(), socketProperties.getAppWriteBufSize(), socketProperties.getDirectBuffer()); if (isSSLEnabled()) { channel = new SecureNioChannel(socket, bufhandler, selectorPool, this); } else { channel = new NioChannel(socket, bufhandler); } } else { channel.setIOChannel(socket); channel.reset(); } getPoller0().register(channel); } catch (Throwable t) { ...... return false; } return true; }
|
可以看到,首先会先设置SocketChannel为非阻塞,然后拿到它内部的Socket进行基础的参数配置,要清楚一点,SocketChannel只是Java Nio出来后为了实现非阻塞弄出来的一套Api,内部实现还是用的Socket。接着会尝试从缓冲区nioChannels从拿到可以复用的实例对象,没有则创建新的,注意创建的时候需要一个实例对象SocketBufferHandler,因为Nio进行读写数据都是通过Bytebuffer,所以这是为了NioChannel内部方便进行Bytebuffer的分配、扩容、管理使用的。最后看到会把NioChannel注册到Poller里面,继续跟进行getPoller0().register()方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
| public void register(final NioChannel socket) { socket.setPoller(this); NioSocketWrapper ka = new NioSocketWrapper(socket, NioEndpoint.this); socket.setSocketWrapper(ka); ka.setPoller(this); ka.setReadTimeout(getConnectionTimeout()); ka.setWriteTimeout(getConnectionTimeout()); ka.setKeepAliveLeft(NioEndpoint.this.getMaxKeepAliveRequests()); ka.setSecure(isSSLEnabled()); PollerEvent r = eventCache.pop(); ka.interestOps(SelectionKey.OP_READ); if ( r==null) r = new PollerEvent(socket,ka,OP_REGISTER); else r.reset(socket,ka,OP_REGISTER); addEvent(r); }
|
到这里NioChannel又被加了一层包装NioSocketWrapper,接着会从事件队列的缓冲区eventCache里面拿到一个事件,并设置事件类型为OP_REGISTER,接着把事件添加到了Poller内部的事件队列。
Poller
接着直接看到Poller线程的run方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63
| public void run() { while (true) { boolean hasEvents = false; try { if (!close) { hasEvents = events(); if (wakeupCounter.getAndSet(-1) > 0) { keyCount = selector.selectNow(); } else { keyCount = selector.select(selectorTimeout); } wakeupCounter.set(0); } if (close) { events(); timeout(0, false); try { selector.close(); } catch (IOException ioe) { log.error(sm.getString("endpoint.nio.selectorCloseFail"), ioe); } break; } } catch (Throwable x) { ExceptionUtils.handleThrowable(x); log.error("",x); continue; } if ( keyCount == 0 ) hasEvents = (hasEvents | events()); Iterator<SelectionKey> iterator = keyCount > 0 ? selector.selectedKeys().iterator() : null; while (iterator != null && iterator.hasNext()) { SelectionKey sk = iterator.next(); NioSocketWrapper attachment = (NioSocketWrapper)sk.attachment(); if (attachment == null) { iterator.remove(); } else { iterator.remove(); processKey(sk, attachment); } } timeout(keyCount,hasEvents); } getStopLatch().countDown(); }
|
主要逻辑都已经写清楚了,同样Poller也是在一个while(true)循环进行的,我们前面的时候说过,调用getPoller0().register()只是生成新的事件放到事件队列里面,并还没有注册到selector,粗略一看,Poller的run方法里面有一个events()方法可能是注册的地方,跟进去看看
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
| public boolean events() { boolean result = false; PollerEvent pe = null; for (int i = 0, size = events.size(); i < size && (pe = events.poll()) != null; i++ ) { result = true; try { pe.run(); pe.reset(); if (running && !paused) { eventCache.push(pe); } } catch ( Throwable x ) { log.error("",x); } } return result; }
|
发现这个方法就是从事件队列取出事件,然后调用了事件的run方法,接着跟进去
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39
| public void run() { if (interestOps == OP_REGISTER) { try { socket.getIOChannel().register( socket.getPoller().getSelector(), SelectionKey.OP_READ, socketWrapper); } catch (Exception x) { log.error(sm.getString("endpoint.nio.registerFail"), x); } } else { final SelectionKey key = socket.getIOChannel().keyFor(socket.getPoller().getSelector()); try { if (key == null) { socket.socketWrapper.getEndpoint().countDownConnection(); ((NioSocketWrapper) socket.socketWrapper).closed = true; } else { final NioSocketWrapper socketWrapper = (NioSocketWrapper) key.attachment(); if (socketWrapper != null) { int ops = key.interestOps() | interestOps; socketWrapper.interestOps(ops); key.interestOps(ops); } else { socket.getPoller().cancelledKey(key); } } } catch (CancelledKeyException ckx) { try { socket.getPoller().cancelledKey(key); } catch (Exception ignore) {} } } }
|
可以看到代码,如果感兴趣的事件类型是OP_REGISTER的话(而新连接到来,创建PollerEvent对象时传入的就是OP_REGISTER),直接把SocketChannel注册到Selector,注册了该Channel的读事件,并且把NioSocketWrapper绑定到了注册成功后返回的SelectionKey的attachment中,这样有事件就绪时直接把该对象拿出来,进行后续的读操作,后续的逻辑都有注释就不多说了。
现在看到了最终注册事件的地方,接着回溯到Poller的run方法,可以看到使用selector.select(),等待已连接的通道是否有事件就绪了,然后就是nio标准的写法,再贴一下代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
| // 拿到已经有事件就绪的SelectionKey Iterator<SelectionKey> iterator = keyCount > 0 ? selector.selectedKeys().iterator() : null; while (iterator != null && iterator.hasNext()) { SelectionKey sk = iterator.next(); // 拿到SocketChannel的事件注册到selector时,返回的SelectionKey绑定的对象 NioSocketWrapper attachment = (NioSocketWrapper)sk.attachment(); // Attachment may be null if another thread has called // cancelledKey() if (attachment == null) { iterator.remove(); } else { iterator.remove(); // 绑定的NioSocketWrapper不为空则调用processKey()方法进行事件的处理 processKey(sk, attachment); }
|
可以看到有事件就绪的通道就会调用processKey()方法,这个方法会对已就绪事件的类型进行判断,最后调用到AbstarcEndpoint里面的processSocket(),直接上代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
| public boolean processSocket(SocketWrapperBase<S> socketWrapper, SocketEvent event, boolean dispatch) { try { if (socketWrapper == null) { return false; } SocketProcessorBase<S> sc = processorCache.pop(); if (sc == null) { sc = createSocketProcessor(socketWrapper, event); } else { sc.reset(socketWrapper, event); } Executor executor = getExecutor(); if (dispatch && executor != null) { executor.execute(sc); } else { sc.run(); } } catch (RejectedExecutionException ree) { ...... return false; } return true; }
|
这里就会看到从processorCache里面拿到SocketProcessor对象,并且给它赋值NioSocketWrapper和event后会放到线程池中去处理,这个SocketProcessor主要做了这么一件事
1
| state = getHandler().process(socketWrapper, event);
|
getHandler()也就是开始提到的ConnectionHandler,它的process()代码较多,这里就不贴出来了,总的来说主要就是创建Http11Processor的实例,并且把它与NioChannel建立映射,如果下次还有这个连接的请求到来,会从map中复用同一个Http11Processor。接着会调用processor.process()方法,最终会调用到Http11Processor的service()。
Processor
虽然看代码实际点,但这几个地方细节太多,而且很多与主线无关的逻辑,就直接总结一下Http11Processor主要做了以下几件事
- Http11Processor内部持有Http11InputBuffer和Http11OutputBuffer两个类,这两个类会分别绑定到org.apache.coyote.Request和org.apache.coyote.Response对象,这两个类又会绑定了NioSocketWrapper,所有的读写还是通过NioSocketWrapper来进行的。接着在service()方法会通过Http11InputBuffer读取连接通道里面的数据到缓冲区,然后进行预处理,解析请求行和请求头。
- 把解析的结果填充到request和response实例对象,接着会调用getAdapter().service()方法,传入request和response对象,这个Adapter对应的实例是CoyoteAdapter,用来将request和response适配到Servlet中的HttpServletRequest和HttpServletResponse接口,Tomcat对应的实现类是org.apache.catalina.connector.Request和org.apache.catalina.connector.Response。
最后还是借一张图片来看看整个过程
CoyoteAdapter
Adapter的主要职责是为了解耦,因为完全可以在Connector(连接器)里面直接调用方法进入Contaienr(容器)的,但由于这两者之间并无太多关联,对与Connector来说,应用层可以有多种协议,IO模型也可以有多种,但这些东西Container并不关心,Container只需要上层包装好的满足Servlet规范的接口实现类即可,所以用了Adapter来连接这两个模块,并且Adapter里面还可以做一些公用的全局管理的逻辑,Adapter的实现类CoyoteAdapter会对request和response进行进一步处理,如请求uri是否可以进一步处理(也就是使用url拼接的方式进行传参),解析cookie中的sessionId和ssl的session,并且添加了对异步Servlet的支持以及完成后数据缓冲区的刷新。上面说了中转,所以实现类里有这么一句逻辑来进入到容器
1 2
| connector.getService().getContainer().getPipeline().getFirst().invoke( request, response);
|
也就是调用Service中的第一个容器Engine内部的Pipeline的第一个Valve,把reques和response对象传进去,接着每个容器的的Pipeline中的基础Valve,也就是StandardxxxValve,都会调用类似的逻辑进入到下一层容器,如果子容器有多个就会使用之前设置好的Mapper进行路由,直到到达Wrapper后,就会通过反射来实例化Servlet对象,过滤器也就是在这一层做的,最终会调用到Servlet的service()方法,篇幅有限,容器这里就不多费口舌了。最后还要了解清楚Endpoint初始化时提到的NioSelectorPool对象,才算是真正清楚了数据读写的流程。
NioSelectorPool
前面说过Poller被称为主selector,而NioSelectorPool被称为辅助selector,所以最后一个知识点就是来探索一下NioSelectorPool究竟做了哪些工作。首先要先搞清楚一点,我们前面所说的最终数据的读写都是使用的NioSocketWrapper,是因为NioSocketWrapper内部持有NioChannel,而NioChannel又是对SocketChannel的包装,所以最终的处理很自然的想到直接在这个类里面调用SocketChannel的read()或write()就完事了,但实际情况可能没想象中的那么好。想想这么一种情况,前面说过Poller内部的selector在检测到有读、写事件就绪的时候,最终会把对应的连接通道读写的处理放到线程池中,所以只要读写没完成,当前的连接通道会一直占用着线程池中的工作线程。如果数据的读写能正常进行还好,但如果由于网络等原因连接通道暂时不能读取数据,要么我们等待读写超时直接放弃掉读写数据的连接通道,但如果这个连接通道马上可以进行数据的读写处理了,又要重新建立连接,进行一系列的调度;要么等到超时的时候,把连接通道重新注册读、写事件到主selector(Poller),但关键是如果连接还是不能正常使用的话,就会白白的造成selector进行空轮询的消耗,并且即使有读、写事件就绪了,还是得经历一系列调度然后再从主线程(Poller)切换到工作线程(线程池的线程),增加了线程上下文的切换的消耗。可能听来没什么感觉,但这是服务器端程序,我们希望的是能管理大量的连接和请求的快速响应,由于特殊原因造成大量的连接占用了可以正常进行数据读写的连接通道所需的资源,这当然不是我们所期望的,所以为了在连接的管理和响应之间进行协调,Tomcat加入了一个组件NioSelectorPool,用来作channel读写超时的监控与连接的辅助管理,之前在Endpoint初始化时,调用了NioSelectorPool的open(),可以看看代码
1 2 3 4 5 6 7 8
| public void open() throws IOException { enabled = true; getSharedSelector(); if (SHARED) { blockingSelector = new NioBlockingSelector(); blockingSelector.open(getSharedSelector()); } }
|
首先会调用一个方法getSharedSelector()方法,这个方法会使用双重校验锁的方式实例化一个selector单例,接下来会判断如果是共享(SHARED),就实例化一个NioBlockingSelector对象,这里先说明一下,这个SHARED表示的含义是NioSelectorPool是否共享同一个selector(默认为true),如果不共享那么NioSelectorPool内部会维护一个selector池,selector不够用时则创建新的selector。接着后面的代码,blockingSelector会调用一个open()方法,它里面的逻辑就是把当前的selector赋值给它内部的selector,并且启动一个BlockPoller轮询器线程,这个BlockPoller与Poller做的事情类似。再来看到NioSocketWrapper,它内部也会获取到EndPoint中NioSelectorPool的实例,这里以读操作来分析,它的read()方法最终会调用到这么一个方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33
| private int fillReadBuffer(boolean block, ByteBuffer to) throws IOException { int nRead; NioChannel channel = getSocket(); if (block) { Selector selector = null; try { selector = pool.get(); } catch (IOException x) { } try { NioEndpoint.NioSocketWrapper att = (NioEndpoint.NioSocketWrapper) channel .getAttachment(); if (att == null) { throw new IOException("Key must be cancelled."); } nRead = pool.read(to, channel, selector, att.getReadTimeout()); } finally { if (selector != null) { pool.put(selector); } } } else { nRead = channel.read(to); if (nRead == -1) { throw new EOFException(); } } return nRead; }
|
这里可以看到,首先会进行判断,如果是非阻塞则会直接调用channel.read()就完事了,但如果是阻塞会调用到pool里面的read()方法,接着跟进去这个方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57
| public int read(ByteBuffer buf, NioChannel socket, Selector selector, long readTimeout, boolean block) throws IOException { if ( SHARED && block ) { return blockingSelector.read(buf,socket,readTimeout); } SelectionKey key = null; int read = 0; boolean timedout = false; int keycount = 1; long time = System.currentTimeMillis(); try { while ( (!timedout) ) { int cnt = 0; if ( keycount > 0 ) { cnt = socket.read(buf); if (cnt == -1) { if (read == 0) { read = -1; } break; } read += cnt; if (cnt > 0) continue; if (cnt==0 && (read>0 || (!block) ) ) break; } if ( selector != null ) { if (key==null) key = socket.getIOChannel().register(selector, SelectionKey.OP_READ); else key.interestOps(SelectionKey.OP_READ); if (readTimeout==0) { timedout = (read==0); } else if (readTimeout<0) { keycount = selector.select(); } else { keycount = selector.select(readTimeout); } } if (readTimeout > 0 && (selector == null || keycount == 0) ) timedout = (System.currentTimeMillis()-time)>=readTimeout; } if ( timedout ) throw new SocketTimeoutException(); } finally { if (key != null) { key.cancel(); if (selector != null) selector.selectNow(); } } return read; }
|
可以看到,首先到NioSocketWrapper的read()到这里后,会判断是否是共享并且使用阻塞的方式(这里传入的直接是true,所以只要判断SHARED),是的话直接调用blockingSelector.read()方法。我们可以先看看不满足情况下,后面的逻辑,会在一个while()循环,首先直接尝试读数据,如果读到了数据会继续尝试下一次读,如果没读到会重新把当前的channel注册读事件到当前的selector,然后会调用selector.select()进行阻塞,直到有读事件就绪,就会再去读数据,阻塞的时间如果达到超时时间就会立即返回,如果channel最后还是没有事件就绪的话,就会退出循环,抛出超时异常。可以看到这里selector的用法跟常规的不一样,逻辑走到我们肯定是不用共享selector或者使用非阻塞,但之前调用的时候就是当作阻塞来处理的,所以这里其实是使用了selector池,也就是说会对每一个SocketChannel分配一个selector来进行超时监控,有数据读直接就完事了,开始没读到数据的话也还是会将事件重新注册到当前的selector,最多等待设置的超时的时间,这样也不关主selector(Poller)什么事了。接看到进入到BlockingSelector的情况,直接看代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41
| public int read(ByteBuffer buf, NioChannel socket, long readTimeout) throws IOException { ...... NioSocketWrapper att = (NioSocketWrapper) key.attachment(); int read = 0; boolean timedout = false; int keycount = 1; long time = System.currentTimeMillis(); try { while(!timedout) { if (keycount > 0) { read = socket.read(buf); if (read != 0) { break; } } try { if ( att.getReadLatch()==null || att.getReadLatch().getCount()==0) att.startReadLatch(1); poller.add(att,SelectionKey.OP_READ, reference); if (readTimeout < 0) { att.awaitReadLatch(Long.MAX_VALUE, TimeUnit.MILLISECONDS); } else { att.awaitReadLatch(readTimeout, TimeUnit.MILLISECONDS); } } catch (InterruptedException ignore) { } ...... if (readTimeout >= 0 && (keycount == 0)) timedout = (System.currentTimeMillis() - time) >= readTimeout; } if (timedout) throw new SocketTimeoutException(); } finally { ...... } return read; }
|
可以看到从逻辑上,与NioSelectorPool里面的read()做的事情是类似的,只是这里因为是使用的共享selector,所以使用了att.awaitxxxLatch()方法来计数,也就是NioSocketWrapper里面的这几个方法
1 2 3 4 5 6 7 8 9
| protected void awaitLatch(CountDownLatch latch, long timeout, TimeUnit unit) throws InterruptedException { if ( latch == null ) throw new IllegalStateException("Latch cannot be null"); latch.await(timeout,unit); } public void awaitReadLatch(long timeout, TimeUnit unit) throws InterruptedException { awaitLatch(readLatch,timeout,unit);} public void awaitWriteLatch(long timeout, TimeUnit unit) throws InterruptedException { awaitLatch(writeLatch,timeout,unit);}
|
也就是使用的CountDownLatch来作为超时的倒计时器,各个NioSocketWrapper相互之间不会受到影响,现在关键是要搞清楚这里阻塞了,在哪里进行收到通知解除阻塞。前面使用selector池时,因为每个SocketChannel是单独的selector监控和管理;这里使用共享的方式,关键依赖的就是BlockPoller了,前面说过它与Poller类似,同样的是从事件队列里面取出事件然后在selector里面进行注册,因为是管理多个SocketChannel,必然要查询有事件就绪的channel,然后分别处理,所以它的run方法里面有这么一段代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
| Iterator<SelectionKey> iterator = keyCount > 0 ? selector.selectedKeys().iterator() : null; while (run && iterator != null && iterator.hasNext()) { SelectionKey sk = iterator.next(); NioSocketWrapper attachment = (NioSocketWrapper)sk.attachment(); try { iterator.remove(); sk.interestOps(sk.interestOps() & (~sk.readyOps())); if ( sk.isReadable() ) { countDown(attachment.getReadLatch()); } if (sk.isWritable()) { countDown(attachment.getWriteLatch()); } }catch (CancelledKeyException ckx) { sk.cancel(); countDown(attachment.getReadLatch()); countDown(attachment.getWriteLatch()); } }
|
熟悉的代码,可以看到拿到读、写事件就绪的SocketChannel对应的SelectionKey后,会先取消事件,防止下次仍然被查询出来,然后就会根据事件类型进行判断,最后会调用countDown()方法来通知之前在NioBlockingSelector.read()里面阻塞的地方,接着循环开始下一轮,又可以读数据了。到这里,读写数据的流程就清楚了,这里还有需要注意的点是,NioSocketWrapper的read()方法是阻塞时才会使用NioSelectorPool进行处理,否则直接调用channel的read()方法;对于write()而言,是直接就丢到NioSelectorPool里面进行处理的,因为到需要响应数据时,已经经历了连接的建立、数据的读取与解析、业务的处理这些过程了,所以写数据对速度更加有要求,一般情况下都能正常写,但网络不通畅或者需要持续写数据的时候,如果重新再从Poller里面来进行调度,未免浪费时间,直接在辅助selector内部处理了,不需要切换线程,也能让数据响应的时间更快。最后再总结一下NioSelectorPool的工作方式和作用
- 两种方式: 第一种使用共享的selector来处理多个SocketChannel,也就是NioBlockingSelector中启用单独的线程BlockPoller会进行通道是否有事件就绪的查询;第二种是非共享的方式,也就直接在NioSelectorPool里面维护了一个selector池,为每个channel分配一个selector进行超时监控,selector用完则重新丢回selector池。
- 作为辅助的selector,能提高主selector(Poller)处理并发连接的数量,对读写的超时进行监控,网络连接较慢时或者需要持续读写时能减少从主线程(Poller)到工作线程(线程池中的线程)的线程上下文切换和调度的开销。
结尾
这篇博客从源码入手,分析了Tomcat的初始化、启动和从建立连接到数据读写的过程,比较大的体会魔鬼藏在细节中,读这种源码时即使是断点调试一步步跟进,也会由于分支太多,很容易偏移主线,所以一定要先在宏观上有一个整体的把握,再带着问题去研究具体的模块才能有比较好的效果。
参考
https://dbaplus.cn/news-134-1990-1.html
https://time.geekbang.org/column/intro/180
http://www.10tiao.com/html/308/201606/2650075890/1.html
https://gearever.iteye.com/blog/1844203
https://www.linuxidc.com/Linux/2015-02/113900p2.htm


